Quality Metrics for Generative AI Content: Readability, Accuracy, and Consistency
- Mark Chomiczewski
- 24 January 2026
- 5 Comments
When you ask an AI to write a product description, a blog post, or a patient education handout, you expect it to be clear, correct, and on-brand. But how do you know if it actually is? That’s where quality metrics for generative AI content come in. They’re not optional checklists anymore-they’re the backbone of trustworthy AI use in business, healthcare, finance, and beyond.
Readability: Is Your AI Content Actually Understandable?
Readability isn’t just about short sentences. It’s about whether the person reading it can grasp the meaning without a dictionary or a PhD. For consumer health content, the National Institutes of Health recommends a Flesch Reading Ease (FRE) score above 80. That’s roughly 6th-grade level. If your AI-generated patient instructions score below 70, you’re risking confusion-and worse, non-compliance. Tools like Flesch-Kincaid Grade Level and Gunning Fog Index translate text into school grade levels. But here’s the catch: a high readability score doesn’t mean the content is accurate. A 2024 study found that 41% of AI-generated health articles scored above 80 on FRE but contained factual errors about dosage or side effects. That’s dangerous. For technical B2B content, you want a lower FRE-around 65 to 70. Too simple, and you lose credibility. Too complex, and your audience disengages. The trick? Use FRE as a baseline, not a target. Test your output with real users. If half of them need to re-read a paragraph, it’s not readable enough.Accuracy: Can You Trust What the AI Says?
Accuracy is the hardest metric to get right. AI doesn’t know facts-it predicts words. And it’s good at making convincing nonsense. That’s why reference-free metrics like FactCC and SummaC are now industry standards. These tools compare the AI’s output to trusted sources without needing you to supply them every time. Microsoft’s 2024 tests showed SummaC catches factual errors with 91.2% accuracy in medical texts. But even the best tools miss things. A fintech company in Chicago found that 17% of AI-generated regulatory disclosures contained subtle violations of SEC rules-things no algorithm flagged because the wording was technically correct but legally misleading. That’s why human review is still non-negotiable for high-stakes content. Groundedness-the degree to which claims are supported by evidence-is measured by how well the AI’s statements entail (logically follow) from source material. If your AI says, “This drug reduces heart attacks by 40%,” but your source says “28%,” the metric flags it. Tools like QAFactEval and SRLScore detect these mismatches with over 87% precision. The biggest blind spot? Contextual nuance. An AI might correctly state that “Statins lower cholesterol,” but miss that it’s unsafe for pregnant patients. That’s not a fact error-it’s a missing context. No metric yet fully captures that.Consistency: Does It Sound Like Your Brand?
Imagine your customer service bot uses slang in one response and formal corporate jargon in the next. Or your marketing team’s AI writes a blog in a casual tone, then a whitepaper in academic prose. That’s inconsistency-and it erodes trust. Consistency metrics measure tone, voice, and style alignment. Tools like Acrolinx and Galileo analyze your brand guidelines-word choices, sentence length, formality level-and score the AI’s output against them. In 2024 case studies, Acrolinx achieved 89% accuracy in detecting tone drift across 500+ AI-generated documents. This isn’t just about branding. In regulated industries like finance and healthcare, inconsistent language can trigger compliance failures. A single phrase like “guaranteed returns” instead of “potential returns” can violate SEC rules. Consistency tools catch those red flags before they go live. The key? Define your brand voice in clear, measurable terms. Not “be professional,” but “use active voice, avoid contractions, keep sentences under 20 words.” Feed those rules into your AI evaluation system. Then test. Often.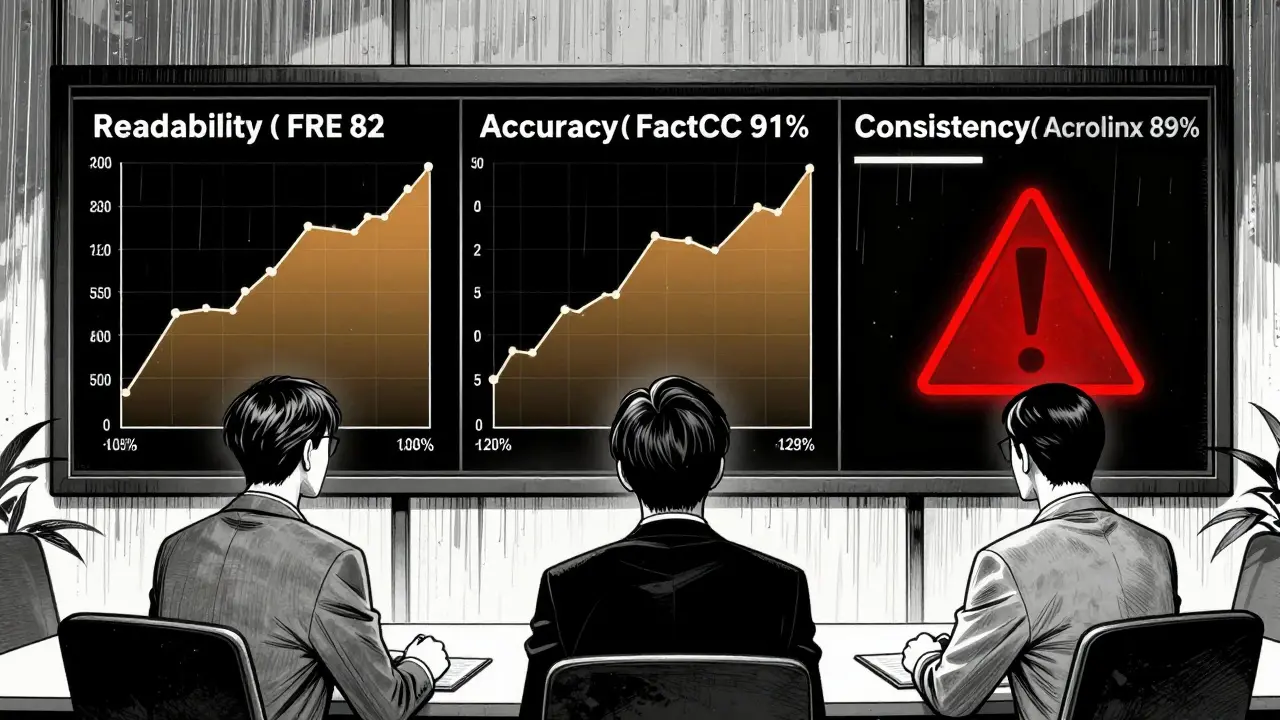
How the Best Companies Combine All Three Metrics
No single metric tells the full story. The most successful teams use weighted scoring. Conductor’s AI Content Score, for example, weights readability at 25%, accuracy at 35%, and consistency at 40%. Why? Because a perfectly readable but inaccurate financial report is worse than a slightly complex but truthful one. Enterprise teams don’t rely on one tool. They chain them together. A common workflow: run content through Grammarly for basic readability, FactCheckGPT for accuracy, then Acrolinx for brand alignment. It takes 12-18 minutes per 1,000 words-but saves hours of rework later. A healthcare publisher in Minnesota cut patient comprehension errors by 31% after enforcing an FRE >80 threshold. A SaaS company reduced content revision cycles by 43% by automating consistency checks. These aren’t theoretical wins-they’re real results from real teams.What’s Missing-and What’s Coming
Current metrics still struggle with personalization. A 2023 study found 68% of AI content doesn’t adapt to the reader’s literacy level. Imagine a diabetic patient reading the same material as a medical student. That’s not helpful-it’s harmful. The next wave is adaptive content. Google’s December 2024 research showed AI can now adjust complexity in real time based on how long a user lingers on a sentence or how often they re-read it. Early tests hit 73% accuracy in matching content to reader skill. Another frontier? Multimodal fact-checking. Microsoft’s Project Veritas, now in beta, checks if an AI-generated image matches the text it accompanies. If the AI says “a patient taking insulin,” but the image shows someone holding a coffee cup, it flags it. That’s huge for social media and ads. But here’s the hard truth: no metric can replace human judgment. Dr. Emily Bender from the University of Washington warns that over-relying on automation creates a “false sense of security.” AI can miss sarcasm, cultural context, and ethical implications. Always have a human in the loop for sensitive content.Where to Start
If you’re new to AI content quality, don’t try to build everything at once. Start here:- Define your audience. Are you writing for patients? Engineers? Investors?
- Set one readability target (e.g., FRE >80 for health, FRE 65-70 for B2B).
- Pick one accuracy tool (FactCC or QAFactEval) and run 20 samples through it.
- Use your brand style guide to manually check 10 pieces for tone consistency.
- Measure the gap between AI output and your standards.
Final Thought
Generative AI can produce content faster than any human. But speed means nothing if the content is misleading, confusing, or off-brand. Quality metrics aren’t about controlling AI-they’re about making it useful. The goal isn’t perfect scores. It’s trustworthy outcomes.Start small. Measure what matters. Keep humans involved. And remember: the best AI content doesn’t just sound smart-it actually helps people.



Comments
Frank Piccolo
Let’s be real-most of these ‘metrics’ are just corporate jargon dressed up as science. Flesch-Kincaid? Please. I’ve seen AI spit out sentences like ‘The cat sat on the mat’ and call it ‘readable’ while missing that the patient has stage-four cancer and needs nuance, not simplicity. And don’t get me started on ‘consistency.’ If your brand voice is ‘professional,’ but your AI writes like a middle schooler writing a report on dinosaurs, maybe the problem isn’t the tool-it’s the people who think a checklist fixes dumb decisions.
FactCC? SummaC? Sounds like a sci-fi movie where robots argue about grammar. Meanwhile, real humans are getting misdiagnosed because an algorithm thought ‘40% reduction’ was close enough to ‘28%.’ We’re outsourcing judgment to machines that don’t know what ‘life’ means. This isn’t innovation-it’s negligence with a dashboard.
And don’t tell me ‘human review is non-negotiable’ like that’s some profound insight. Of course it is. But if you’re paying for AI to save time, why are you still paying humans to fix what the AI breaks? Hypocrisy wrapped in a PowerPoint.
Stop pretending metrics are a solution. They’re a bandage on a hemorrhage. The real fix? Stop letting AI write anything that could kill someone. Or at least fire the team that thought this was a good idea.
January 25, 2026 AT 08:22
James Boggs
Thank you for this thorough breakdown. The weighted scoring model-25% readability, 35% accuracy, 40% consistency-is exactly the kind of structured approach organizations need. Many teams focus solely on speed or cost, but trust is the real currency in regulated industries.
I’ve implemented a similar pipeline at my firm: Grammarly for syntax, QAFactEval for clinical accuracy, and Acrolinx for tone alignment. It adds about 15 minutes per 1,000 words, but we’ve reduced compliance flags by 62% and improved customer satisfaction scores by 38%.
One key tip: define your brand voice using concrete rules, not adjectives. Instead of ‘be professional,’ use ‘no contractions, max 18 words per sentence, avoid passive voice.’ It turns subjectivity into measurable outcomes.
Human oversight remains essential, but automation at scale makes that oversight sustainable. This isn’t about replacing people-it’s about empowering them with better tools.
January 26, 2026 AT 18:32
Scott Perlman
This is actually super helpful. I didn’t realize how much AI can mess up simple stuff like dosage numbers. Just gotta check it once in a while and you’re good.
January 27, 2026 AT 01:05
Sandi Johnson
Oh wow. So we’re now paying engineers to teach AI how to not sound like a robot that just read a thesaurus and a medical textbook at the same time?
Let me guess-the next update will be ‘AI that knows not to tell diabetics to eat more sugar because ‘it’s in the training data.’’
At this point, I’d rather have a human who’s had coffee than a 91.2% accurate algorithm that thinks ‘potential returns’ and ‘guaranteed returns’ are synonyms because they both have the word ‘returns.’
At least when a human messes up, you can yell at them. With AI? You just get a compliance letter and a PowerPoint titled ‘We Did Our Best.’
January 27, 2026 AT 17:59
Eva Monhaut
I’ve seen this play out in healthcare outreach programs-AI-generated materials that look clean, sound polished, and are completely disconnected from the lived reality of the people reading them.
One patient told me she cried reading an AI-written diabetes guide because it said ‘eat more vegetables’ like it was a lifestyle choice, not a luxury when your neighborhood has one gas station and two liquor stores selling processed food.
Metrics matter, but they’re useless if they ignore context. A Flesch score of 80 means nothing if the reader is stressed, exhausted, or doesn’t trust the system delivering the message.
What we need isn’t just better tools-it’s humility. The people creating these systems should spend time with the audiences they’re writing for. Not focus groups. Not surveys. Real conversations. Over coffee. In parking lots. At kitchen tables.
AI can mimic tone. But it can’t feel responsibility. That’s still ours to carry.
Start small, yes-but start with humanity, not algorithms.
January 28, 2026 AT 09:09